Obfuscation
Obfuscation of code is a technique used to transform plain, easy-to-read code into a new version that is deliberately hard to understand and reverse-engineer—both for humans and machines.
Obfuscation has been used in several different programming languages, notably C/C++ (there’s even a competition for obfuscating C code) and Perl. But there’s a language where obfuscation has gained tremendous popularity among developers and business owners alike: JavaScript.
JavaScript is an interpreted language, so client-side JavaScript requires an interpreter in the browser to read it, interpret it, and run it. This also means that anyone can use a browser debugger to easily go through the JS code and read or modify it at will.
With such easy access to client-side JavaScript code, it’s almost effortless for an attacker to take advantage of this security weakness and target any unprotected code.
Companies—notably, the enterprise and Fortune 500—are frequently storing important business logic on the client side of their apps.
If you understand the basics of application security, you know that code secrets should always be kept on trusted execution environments like the backend server. But this is one of those cases where practice takes precedence over theory. When companies store this important logic on the client side, they typically do so because they can’t feasibly keep it on the server side.
A common reason for this is when there’s no backend in the first place, as in the case of some mobile applications. Another example is when there’s some code that’s related to the user experience (like an analytics algorithm) that must run on the client side.
Still, the most common reason is performance. Server calls take time, and when you have a service where performance is crucial—like a streaming platform or an HTML5 game—storing all the JavaScript on the server is not an option.
Whatever the case, companies usually don’t want to expose their proprietary logic. And they definitely never want to expose code secrets. Especially when their competitors can reverse-engineer the code and copy proprietary algorithms.
Besides intellectual property theft, client-side JavaScript can also be targeted in more sophisticated attacks such as automated abuse, piracy, cheating, and data exfiltration.
JavaScript obfuscation is a series of code transformations that turn plain, easy-to-read JS code into a modified version that is extremely hard to understand and reverse-engineer.
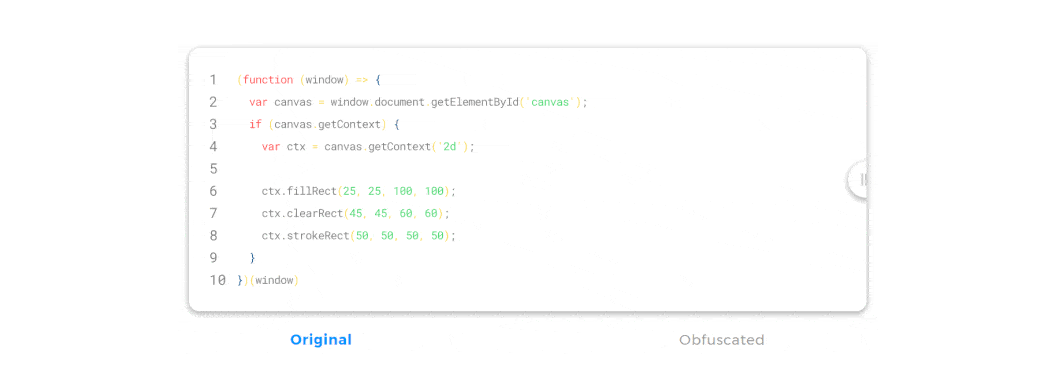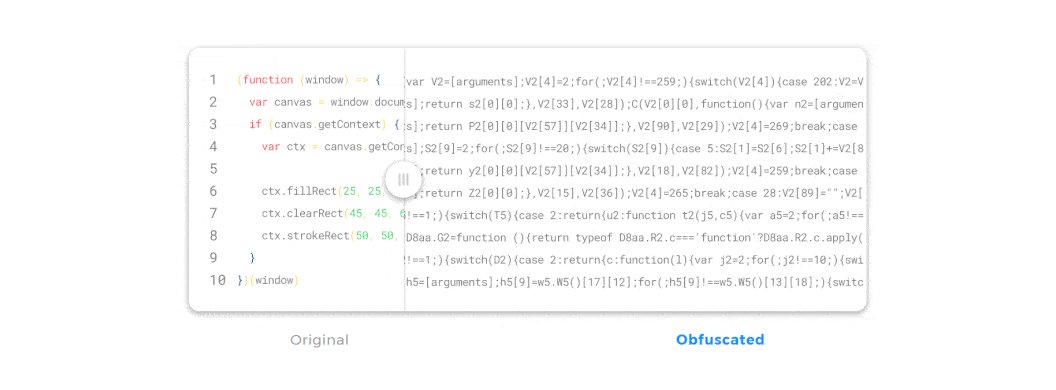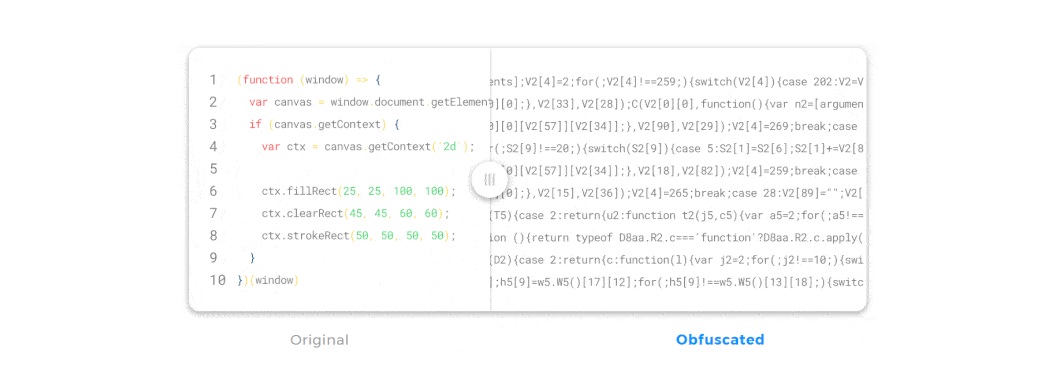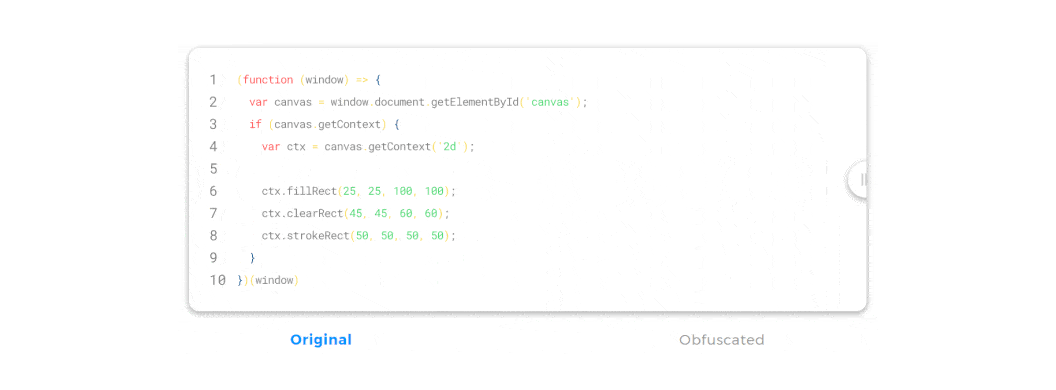
Unlike encryption, where you must supply a password used for decryption, there’s no decryption key in JavaScript obfuscation. In fact, if you encrypt JavaScript on the client side, that would be a pointless effort—if we had a decryption key we needed to supply to the browser, that key could become compromised and the code could be easily accessed.
So, with obfuscation, the browser can access, read, and interpret the obfuscated JavaScript code just as easily as the original, un-obfuscated code. And even though the obfuscated code looks completely different, it will generate precisely the same output in the browser.